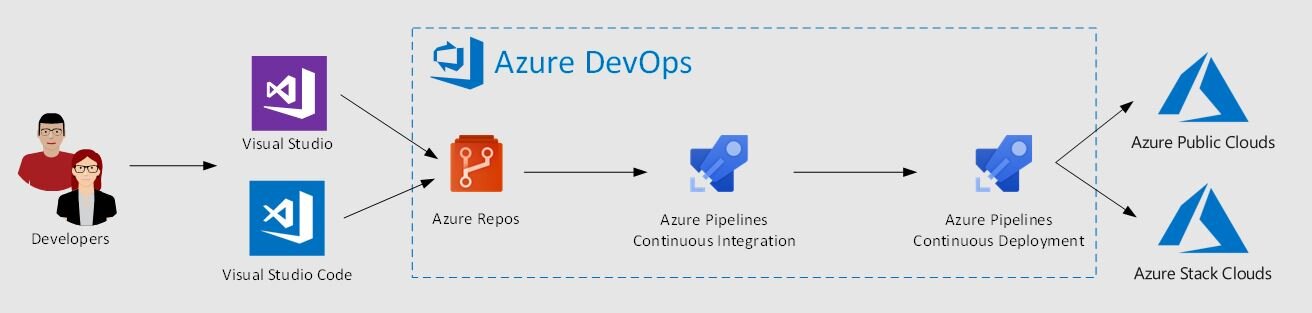
So, like me, you’re thinking of dipping your toes in the new DevOps revolution. You’ve picked an app to start with and spun up an Octopus server. Now what? There are plenty of tutorials about Octopus Deploy that show how to use all of Octopus’s features and also how to integrate with TFS Build, but I have yet to find a good tutorial that shows best practices for a real-world setup of an Octopus project. If you have an application that consists of anything more complicated an Azure WebApp, you'll need to think a little hard about a consistent strategy for managing and configuring your deployment pipeline.
My hope is that this can be one of those guides. As a disclaimer, I am not a DevOps or Octopus expert. I have, however, slogged through the bowels of Octopus trying to get two medium-complexity applications continuously deployed using a Visual Studio Online build and Octopus Deploy. My first foray, though functional, was a disaster to configure and maintain. But I learned a lot in the process. While configuring the second application, I applied what I previously learned and I am much happier with the result.
This first part of the series will lay some foundational guidance around configuring a deployment project. It may not be groundbreaking, but it is an important step for the future installments. So, without further ado, on with the show…
The Application
My application is hosted completely in Azure and my deployment, obviously, is very Azure centric. Having said that, it should be trivial to adapt some of this guidance for on-premise or other cloud providers.
My application consists of:
- SQL Server with multiple databases
- Key Vault
- Service Bus
- Azure Service Fabric containing multiple stateless micro-services and WebAPIs
- Azure WebApp front end
The Service Fabric micro-services are the heart of the system and they communicate with each other via Service Bus queues.
The WebApp is the front end portal to system. It talks to some of the micro-services using their WebAPI endpoints. In hindsight, it would have been easier to host the website as an ASP.NET Core site in the fabric cluster, but unfortunately core wasn't baked yet when we started this project. So, alas, we live with the extra complexity.
Variables
The variable system in Octopus is extremely powerful. The capabilities of variable expansion continue to surprise me. Just when I think I’m going to break it using a hair-brained scheme, it effortlessly carries on bending to my will. Good job Octopus team! But, as my Uncle Ben always says, “with great power, comes great responsibility” (sorry).
I’m going to assume you already have a cursory understanding the variable system in Octopus. If not, please read their great documentation and then come back. All set? Good.
Variable Sets
The first hard lesson I learned was to use variable sets right from the beginning. It is tempting to shove all of your variables in the project itself, and that’s exactly how I started. This is probably fine at first, though hard to manage when your variable count grows large. But, you will soon come to a point where one of two things will happen:
- Your variable count grows so large that it’s hard to maintain and conceptualize.
- You want to split your project in half or add a new project, and you want to share the variables between the related projects.
Personally, I hit the latter. "Well," I thought, :I’ll just move all my variables into a variable set that I can share between my projects." Not so fast, mon frère! You see, there is no UI feature that allows you to move a variable from a project to a variable set, nor from a variable set to another variable set. So, you’re stuck with recreating all of your variables by hand, or using the Octopus REST APIs to copy from one to the other. The latter works fine, until you hit sensitive variables. You cannot retrieve sensitive variable values using the UI or the REST API, so your stuck with entering it again from the sticky note on your monitor (shame on you!). This why deciding on a variable set scheme is crucial right up front.
Ok, so we’re all agreed that you should create variable sets right away. But, you ask, should I create just one big one? Well, if you just create one variable set, you’ve solved issue #2, but not #1. Your variable set can still get pretty long and while Octopus does sort the variables by name, it can still be difficult to find the variable you want when the page seems to scroll indefinitely. So, I recommend creating a set of variable sets. While it is a bit more work to set everything up just right, trust me when I say, you will thank me later.
You can use any segregation scheme you wish, but I used these criteria for my variable sets:
- Resource Level
These types of variable sets contain infrastructure level variables that have no concept of the applications that run on top of them. For instance, a SQL Server variable set may contain the name of the SQL Service instance, admin login and password, but not any of the application level database information (especially in my case where each micro-service uses an isolated database). Another example would be an Active Directory set that contains common things like your TenantId, Tenant Name, etc, but not any AAD application variables that you may want to create. The idea here, is like all infrastructure, you should be able to configure it once and never change it again.
- Application Level
These types of variable sets contain variables that pertain to a logical application, service or component. You may have only one of these, or multiple, depending on your solution. This is where all the magic happens and where you will spend most of your time tweaking as your application changes. Things like app.config settings, AAD Applications, Database names and connection strings, etc. live in these sets. You may have variables in these sets that pertain to several different resource types, but that ok. The point is to group all of your variables pertaining to Component A into a single variable set so you know exactly where to go to change them.
- Project Level
Granted, variables in the project itself are not technically a variable set, but it is useful to think of them as such. These variable should be kept to an absolute minimum since they cannot be shared by other projects. These should contain any overrides that you may need or wrappers around step output variables (more on this in a future post).
Now that you have a handful of variable sets, it’s important to name them appropriately. I used the scheme <ProjectGroup>.<Resource|Component>. Being a C# guy, I like periods instead of spaces, but that just be me. At the end of the day it doesn't really matter, since to Octopus set and variable names are just strings. The <ProjectGroup> part is optional if you only have 1 solution running on your Octopus server, but is crucial as soon as you want to onboard a completely unrelated solution and want to keep any semblance of sanity.
In the end, the naming and segregation scheme is completely up to you. The most important thing is that you thing decide on a scheme and stick to it. It takes much more effort to adapt to a scheme later than to do it up front.
One last convention that I tried to follow with variable sets is to keep the Environment Scoping of variables to a minimum within variable sets. This seems like it wouldn’t be a problem, and may not be for your situation, but if you wind up with multiple Octopus projects with different lifecycles sharing a variable set, it can become problematic. For example, if you are naming your websites differently in each environment (say with a –DEV suffix or something), the answer is NOT to create scoped versions of the website name in the set. The answer IS to use expansion (see further down for this). Anything that must be scoped to environments should either utilize clever expansions or be put in the project-level variables. The only exception I make to this rule is for sensitive data that needs to be shared with multiple Octopus projects and must be different for each environment. SQL admin password is a good example of this. In this case, it is beneficial store that as a scoped variable in the variable set, but you must remember this if you ever change the lifecycle of a project or add a new project with a different lifecycle.
Variable Names
Like variable sets, variables should follow a strict naming scheme. To optimize for the UI sorting, I picked <Resource>.<OptionalSubResource>.<Name>. This helps keep related variables together when viewing the UI. As an example, this is roughly what my variable sets look like for my SQL related variables:
- MyProjectGroup.Database variable set

- MyProjectGroup.MyApplication variable set

Variable Expansion
Variable expansion is one of the features that sets Octopus apart from, say, Visual Studio Online Release Management. In VSO, you can do most anything else, but the VSO variable system is absolutely dwarfed by Octopus. I’ll assume you understand the basics of variable expansion and dive right into my usage of it. My goal was to have a good balance between adhering to the DRY no duplication principal and also having enough extension points in the variable system to change things without having to do large overhauls. To that end, I wind up having a decent amount of variables that simply reference another variable. But, defining it upfront means that I just need to change the variable value rather than creating a new variable and updating all the places in my code/deployment scripts that use the old variable. Make enough changes in your variables and you’ll begin to see how useful this is. The typical way to use variable expansions is to build things like connection strings with them. For example, if you have a database connection string, you could build the connection string by hand and stick it in a single variable and mark the whole thing as sensitive (since it has a password). But, now your stuck if the server or database name changes. Instead, something like this:
| Name |
Value |
| SQL.Name |
MyDatabaseServer |
| SQL.Database.MyApplication.Name |
MyApplication |
| SQL.Database.MyApplication.Password |
******** |
| SQL.Database.MyApplication.Username |
MyApplicationUser |
| SQL.Database.MyApplication.ConnectionString |
Server=tcp:#{SQL.Name}.database.windows.net,1433; Initial Catalog=#{SQL.Database.MyApplication.Name}; Persist Security Info=False; User ID=#{SQL.Database.MyApplication.Username}; Password=#{SQL.Database.MyApplication.Password}; MultipleActiveResultSets=False; Encrypt=True; TrustServerCertificate=False; Connection Timeout=30; |
The cool things is that Octopus is smart enough to know that the password fragment is sensitive and will replace it with stars whenever the connection string's expanded value is put in the logs or deployment output. Score 1 Octopus!
Another use for variable expansion is putting optional environment suffixes (like –DEV) on the names of resources. I’ll get into this in Part 2, but the keen eyed among you may have already spotted it in the screenshots.
Project Setup
Once you get your variable system up and running (I know it took a while), it’s time to create your project. Again, I’ll assume you know or have read about the basics, so I’ll only point out a few nuggets.
Don’t forget to reference all your many variable sets in your project. Also, if you add a new variable set in the future, don’t forget go into your project and add it there. I know it sounds silly to mention this, but trust me, you’ll forget. Ask me how I know...
One of the questions that I had, and to some extent still have, is whether you should break apart your system into multiple projects or a single large project. I have yet to find a compelling argument either way, except to say that Octopus’s guidance is to have a single project and, the approach of multiple projects is only a holdover from previous versions that couldn’t handle multiple steps in a project. While I somewhat agree with this, it is important to understand the tradeoffs of each approach. For the record, I have tried them both and I would tend towards a single project purely for simplicity purposes. I will make one caveat: if you’re planning on deploying your infrastructure as part of your pipeline, consider separating that into it’s own project. I’ll talk more about infrastructure deployment in Part 2.
Single Project
Single projects are generally much easier to manage and maintain. You have to think a little less about making sure your variable are in order and that all the components are on the same version. However, it does mean that you cannot easily rev your components individually. That’s not strictly true because you can set your project to skip steps where the package hasn’t changed, but it does mean that you can’t easily see at a glance what components have changed from version to version.
Having said that, this is still my preferred configuration since I find it much easier to maintain. Especially when you factor in certain common steps like gathering secret keys that can only be retrieved via powershell script (and thus are not part of your variable sets), such as storage account connection strings or AAD application IDs.
Multiple Projects
Having multiple projects does give you a clearer view of what versions of your components are everywhere. It also allows you move up or down with each component. While upgrading specific pieces of your application can be accomplished by careful management of your packages, it is still difficult to rollback a specific component while leaving the rest alone using a single project. You can accomplish this by creating a new release and customizing which packages to use, but man is that annoying!
The other downside of multiple projects is that it is difficult, if not impossible, to manage the timing of deployments. If Component B needs to be deployed only after Component A, there is no way to do it using multiple projects in an automated fashion. You would have to manually publish them in the right order and wait for any dependencies to finish before moving onto the next component. Since I’m looking for Continuous Deployment style pipeline, this is a deal-breaker for me.
In the end, I understand why there is no clear-cut guidance about which approach to use. It really depends on your application. If you have a simple application where all the components are meant to rev together, you should probably pick a single project. If any of your components are designed and expected to rev independently, or you need to very fine grained control over the releases you create, multiple projects might be the right fit.
Build
In my case, I used the VSO build system. All in all it is pretty straightforward on how to build and package your solution. There are really only a few places where you have to make changes.
I’m using GitVersion to automatically increment the build number. I’m also having it apply the version number to my AssemblyInfo files so all of my assemblies match versions.
The next step is to extract the version number from GitVersion and put it in a build variable to so it can be handed off to Octopus to use as the release version. This is convenient because GitVersion uses SemVer, which Octopus understands. So, all the releases created from my CI build are automatically understood by Octopus to be pre-release. Here is the powershell for that task:
[powershell]
$UtcDateTime = (Get-Date).ToUniversalTime()
$FormattedDateTime = (Get-Date -Date $UtcDateTime -Format "yyyyMMdd-HHmmss")
$CI_Version = "$env:GITVERSION_MAJORMINORPATCH-ci-$FormattedDateTime"
Write-Host "CI Version: $CI_Version"
Write-Host ("##vso[task.setvariable variable=CI_Version;]$CI_Version")
[/powershell]
I used OctoPack to package my projects into NuGet packages. To get OctoPack to package your solution, simply add “/p:RunOctoPack=true /p:OctoPackPackageVersion=$(CI_Version) /p:OctoPackPublishPackageToFileShare=$(build.artifactstagingdirectory)\deployment” to the MSBuild arguments of the Visual Studio Build task. Alternatively, you can run a standard Package NuGet task.
Last, but not least, you need to push your packages to your Octopus server. There is an Octopus extension to VSO that does this very nicely. I recommend using that to communicate with the Octopus server. If you don’t have your project set to automatically create a release when a new package is detected, you’ll also need to add a create release task. In that task, I use the same CI_Version variable for the Release Number parameter.
The only question to ask when it comes to your build is the same question asked when creating your Octopus project: Should you create one build or multiple. I would argue that the answer is probably the same as for the project setup. If you need or want granular control the over packages you create, you’ll have to create multiple projects targeted at each component of your application. Unfortunately, VSO does not have any way to customize your build based on which files actually changed in your changesets, therefore a new package version of each component will be created for each build, even if nothing changed in it. For most projects this is acceptable. If it is not, the nearest I have come is to create multiple VSO build definitions, one for each component. In the build triggers tab, I added path filters for all of the projects that affect that component. Make sure that you include any dependencies that your component has. The downside of this is that it can be awfully brittle. You have to be careful to add new path filters for any new dependencies that are added to your projects. In the end, I found it not worth the hassle.
Wrap Up
Hopefully this gave you a good foundation for you Octopus deployment. There wasn’t much that was juicy here and much of it seems tedious and unnecessary, but I guarantee this up front work will pay off greatly in the future as your application evolves, requiring your build and deploy to evolve with it.
In the rest of the series, I will dig a little deeper into the especially tricky components of my sample application and some of the strange and sometimes hacky things I had to do to get Octopus to place nice with them. This will include: deploying my Azure infrastructure, creating/updating an Azure Active Directory application dynamically and deploying a Service Fabric cluster.