
This is part 2 in a series of articles on my experiences of deploying Azure Arc enabled data services on Azure Stack HCI AKS.
Part 1 discusses installation of the tools required to deploy and manage the data controller.
Part 2 describes how to deploy and manage a PostgreSQL hyperscale instance.
Part 3 describes how we can monitor our instances from Azure.
First things first, the PostgreSQL extension needs to be installed within Azure Data Studio. You do this from the Extension pane. Just search for ‘PostgreSQL’ and install, as highlighted in the screen shot below.

I found that with the latest version of the extension (0.2.7 at time of writing) threw an error. The issue lies with the OSS DB Tools Service that gets deployed with the extension, and you can see the error from the message displayed below.

After doing a bit of troubleshooting, I figured out that VCRUNTIME140.DLL was missing from my system. Well, actually, the extension does have a copy of it, but it’s not a part of the PATH, so can’t be used. Until a new version of the extension resolves this issue, there are 2 options you can take to workaround this.
Install the Visual C++ 2015 Redistributable to your system (Preferred!)
Copy VCRUNTIME140.DLL to %SYSTEMROOT% (Most hacky; do this at own risk!)
You can find a copy of the DLL in the extension directory:
%USERPROFILE%\.azuredatastudio\extensions\microsoft.azuredatastudio-postgresql-0.2.7\out\ossdbtoolsservice\Windows\v1.5.0\pgsqltoolsservice\lib\_pydevd_bundle
Make sure to restart Azure Data Studio and check that the problem is resolved by checking the output from the ossdbToolsService. The warning message doesn’t seem to impair the functionality of the extension, so I ignored it.

Now we’re ready to deploy a PostgreSQL cluster. Within ADS, we have two ways to do this.
1. Via the data controller management console:
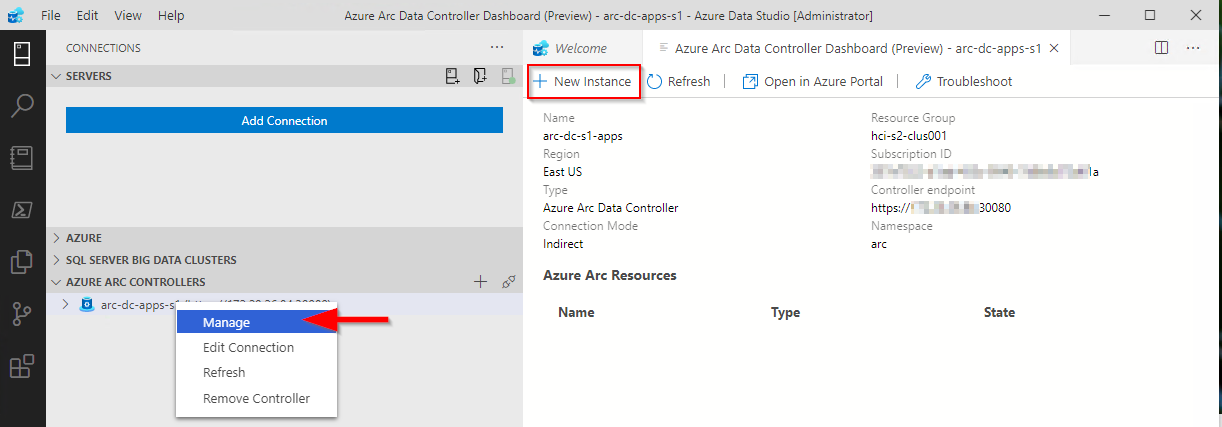
2. From the Connection ‘New Deployment…’ option. Click on the ellipsis (…) to present the option.

Whichever option you choose, the next screen that is presented are similar to one another. The example I‘ve shown is via the ‘New Connection’ path and shows more deployment types. Installing via the data controller dashboard, the list is filtered to what can be deployed to the cluster (the Azure Arc options).

Select PostgreSQL Hyperscale server groups - Azure Arc (preview), make sure that the T&C’s acceptance is checked and then click on Select.
The next pane that’s displayed is where we defined the parameters for the PostgreSQL instance. I’ve highlighted the options you must fill in as a minimum. In the example, I’ve set the number of workers to 3. By default it is set to 0. If you leave it as the default, a single worker is deployed.
Note: If you’re deploying more than one instance to your data controller. make sure to seta unique Port for each server group. The default is 5432

Clicking on Deploy runs through the generated Jupyter notebook.

After a short period (minutes), you should see it has successfully deployed.

ADS doesn’t automatically refresh the data controller instance, so you have to manually do this.

Once refreshed, you will see the instance you have deployed. Right click and select Manage to open the instance management pane.

As you can see, it looks and feels similar to the Azure portal.
If you click on the Kibana or Grafana dashboard links, you can see the logs and performance metrics for the instance.
Note: The Username and password are are what you have set for the data controller, it is not the password you set for the PostgreSQL instance.

Example Kibana logs

Grafana Dashboard
From the management pane, we can also retrieve the connection strings for our PostgreSQL instance. It gives you the details for use with various languages.

Finally in settings, Compute + Storage in theory allows you to change the number of worker nodes and the configuration per node. In reality, this is read-only from within ADS, as changing any of the values and saving them has no effect. If you do want to change the config, we need to revert to the azdata CLI. Jump here to see how you do it.

In order to work with databases and tables on the newly deployed instance, we need to add our new PostgreSQL server to ADS.
From Connection strings on our PostgreSQL dashboard, make a note of the host IP address and port, we’ll need this to add our server instance.

From the Connections pane in ADS, click on Add Connection.
From the new pane enter the parameters:
| Parameter | Value |
|---|---|
| Connection type | PostgreSQL |
| Server name | name you gave to the instance |
| User name | postgres |
| Password | Password you specified for the postgreSQL deployment |
| Database name | Default |
| Server group | Default |
| Name (Optional) | blank |
Click on Advanced, so that you can specify the host IP address and port

Enter the Host IP Address previously noted, and set the port (default is 5432)

Click on OK and then Connect. If all is well, you should see the new connection.

Scaling Your Instance
As mentioned before, if you want to be modify the running configuration of your instance, you’ll have to use the azdata CLI.
First, make sure you are connected and logged in to your data controller.
azdata login --endpoint https://<your dc IP>:30080
Enter the data controller admin username and password

To list the postgreSQL servers that are deployed, run the following command:
azdata arc postgres server list
To show the configuration of the server:
azdata arc postgres server show -n postgres01
Digging through the JSON, we can see that the only resources requested is memory. By default, each node will use 0.25 cores.

I’m going to show how to increase the memory and cores requested. For this example, I want to set 1 core and 512Mb
azdata arc postgres server edit -n postgres01 --cores-request 1 --memory-request 512Mi
If we show the config for our server again, we can see it has been updated successfully

You can also increase the number of workers using the following example
azdata arc postgres server edit -n postgres01 --workers 4Note: With the preview, reducing the number of workers is not supported.

If you do make any changes via azdata, you will need to close existing management panes for the instance and refresh the data controller instance within ADS for them to be reflected.


Currently, there does not appear to be a method to increase the allocated storage via ADS or the CLI, so make sure you provision your storage sizes sufficiently at deployment time.
You can deploy more than one PostgreSQL server group to you data controller, the only thing you will need to change is the name and the port used

You can use this command to show a friendly table of the port that the server is using:
azdata arc postgres server show -n postgres02 --query "{Server:metadata.name, Port:spec.service.port}" --output table
In the next post, I’ll describe how to upload logs and metrics to Azure for your on-prem instances.